I used valgrind --tool=massif <path-to-release-executable> to run the program, made ~10 requests and then used massif-visualizer to look at the results. The memory usage peaks at around 90MiB, and goes down to about 20MiB in between requests. It never goes above 90MiB. I don't belive there's any memory leak here.
Thank you for your answer. Is it stable at around 21MB after your 10 requests, serial or parallel? I conducted an experiment and simulated concurrency 1000 times, and then the program's memory stabilized at around 148MB. As the program's runtime and concurrency increase, will the program's memory continue to grow or reach a certain critical value before being released? If we look at the current phenomenon, there is a risk of leakage.
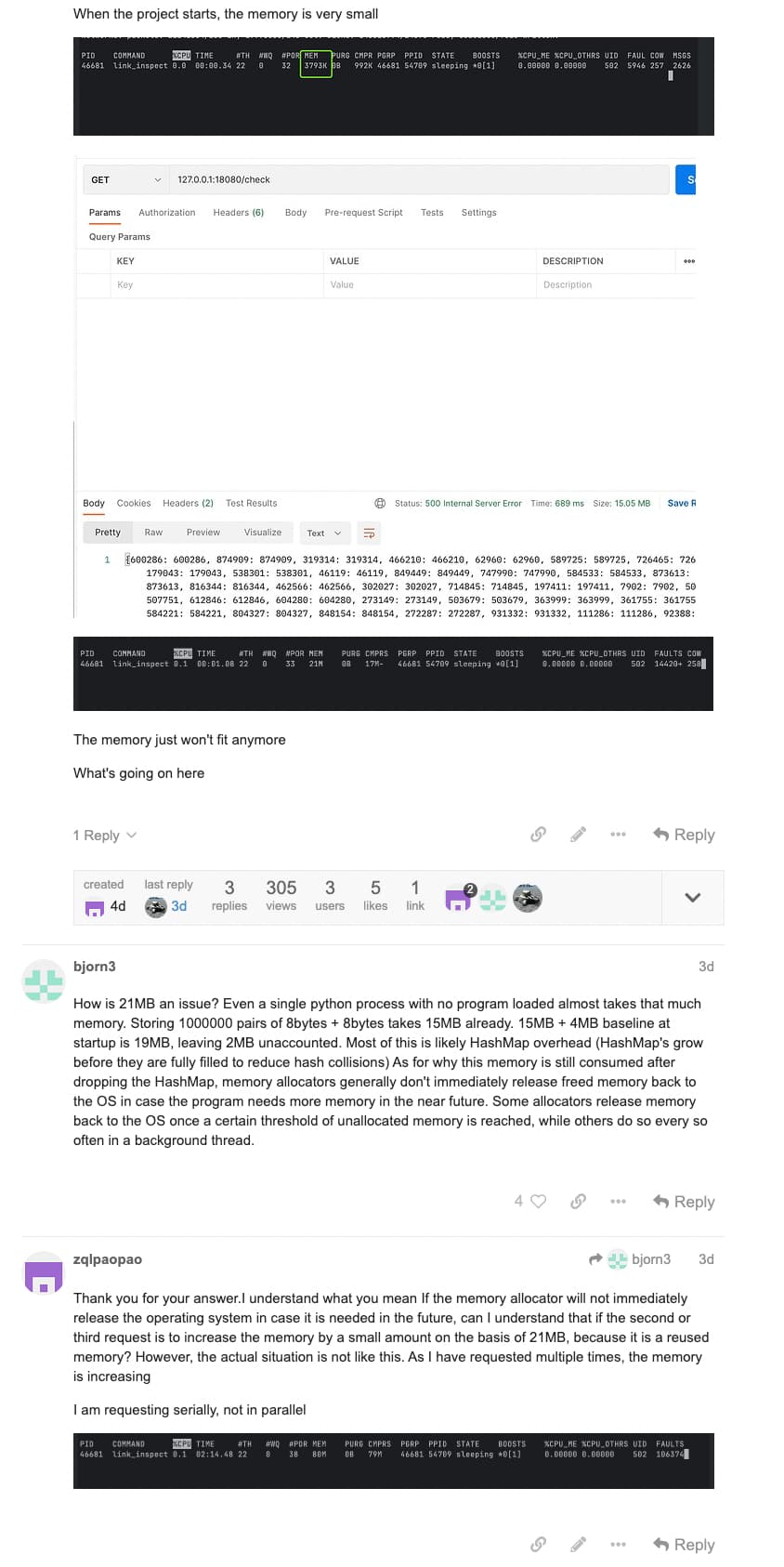
Secondly, I have another question. If I only request once and the program is initialized at around 4m, why is the 21mb of memory not released after the request
Here is my code
package main
import (
"fmt"
"github.com/beego/beego/v2/client/httplib"
"sync"
)
func main() {
var (
url = "http://127.0.0.1:18080/check"
wg = &sync.WaitGroup{}
ch = make(chan struct{}, 1000)
)
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func(wg *sync.WaitGroup) {
for {
select {
case _, ok := <-ch:
if !ok {
goto END
}
l := httplib.Get(url)
if b, err := l.Bytes(); nil != err {
fmt.Println(err)
} else {
fmt.Println(string(b))
}
}
}
END:
wg.Done()
}(wg)
}
for i := 0; i < 1000000; i++ {
ch <- struct{}{}
}
close(ch)
wg.Wait()
}
Maybe you forgot adding .workers(1) before .run() to ensure a serial call.
The more workers you allocate, the more HashMap is created, which result in the increasing of memory usage.
Normally if you us a mechanism based on measurements from the OS (Windows Task Monitor, /usr/bin/time, etc.) the amount of memory reported will actually be what has been requested by the program's allocator. Even after your program frees everything, the allocator won't release that memory back to the OS because it might need that memory again and asking the OS for more memory is expensive.
That means OS measurements tend to report the maximum amount of memory your program has used at any one time, not the actual amount it is using right now.
This StackOverflow answer explains it better than I could:
You are putting a million items into a per-worker HashMap. This program requires an upper bound of 16 MiB * N workers of memory. The only way to improve the memory usage is by changing the requirement.