The amount of query data is also one day, but the search time for cassandra-rs is 1.079947, while the use cassandra-sys-rs is 0.134054.
At first, I only used cassandra-sys-rs for development, but in order to use singleton, I used cassandra-rs to develop....so I asked about the performance. Why is it also based on c++ cassandra, but the performance is very different?
Most likely Rust wrappers have extra abstractions that introduce overhead (talk about zero cost abstractions :D), but to answer your question you'd need to use some profiler tools, preferably with optimizations.
It might just be a case where some #[inline] attributes are needed to collapse simple wrappers in cassandra-rs, but the profiler should tell the actual story.
Because I haven't heard of LTO before, I searched for a link to stackoverflow.
The way to use is to increase lto = true in Cargo.toml? Or is there any other way?
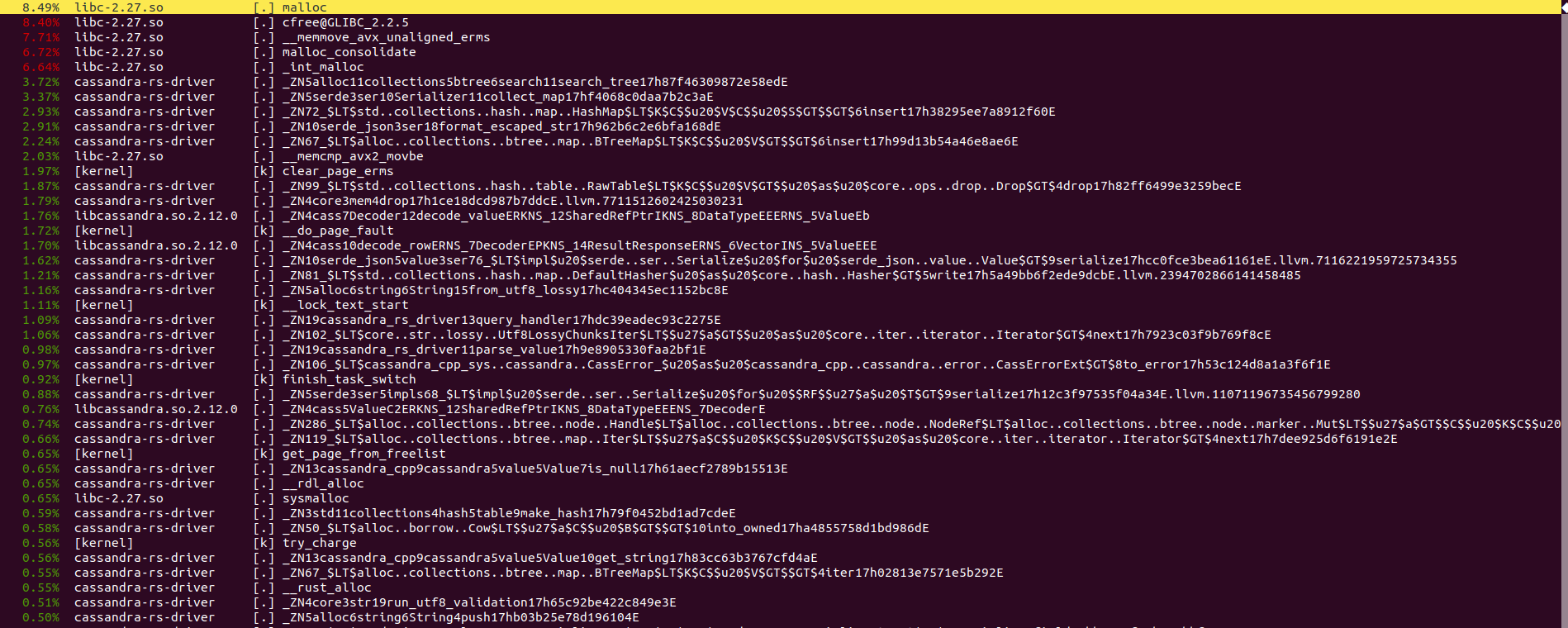
That perf output looks like a lot of short-lived allocations in the Rust layer, likely for managing data structures involving a BTreeMap and HashMap. If the Rust code is doing a bunch of book-keeping like this, it could explain the performance difference you're seeing.
Yes, this is correct, and lto is enabled by default for release builds
As for your output, as @cbiffle mentioned using collections will affect your performance.
So is it used in your code or in code of cassandra wrapper?
If it is your code, one way to optimize it would be to not create these collections each time, but instead store it somewhere for re-use (clearing collections will not de-allocate memory unless you perform it manually) so you'll start saving time on allocations
It could be that the cassandra-rs wrapper is contributing a lot of those allocations too. At a quick glance, I see a lot of owned strings and CString::new. It's hard to avoid that though, because it has to make sure there's a NUL (b'\0') terminator, which a Rust borrowed &str won't usually have.
IIRC, we have two kinds of LTO, "thin" and "full". The "full" one is expensive and was never enabled by default, but I think the "thin" one might have been enabled at some point as it is much lighter-weight (though less capable).