I wanted to try out using async for actors. I read Actors with Tokio – Alice Ryhl which seemed sensible and started coding. Except, I need actors to call other actors. Fine, you get something like:
struct MyActor {
// ...
}
impl MyActor {
async fn handle_message(&mut self, msg: Request) {
match msg.payload {
Request::SomeRequest(reply_channel) => {
let sub_response = self.other_actor_handle.slow_call().await;
self.some_state.update(sub_response);
reply_channel.send(...);
}
// ...
}
}
}
async fn run_my_actor(mut actor: MyActor) {
while let Some(msg) = actor.receiver.recv().await {
actor.handle_message(msg);
}
}
Except that doesn't actually work. Because now MyActor is blocked on the slow_call and can't service other requests while waiting. So you need to throw out the nice call API on the actor handles and do full on message passing between actors. And which point: why even bother with async in the first place?
My use case looks like the following diagram:
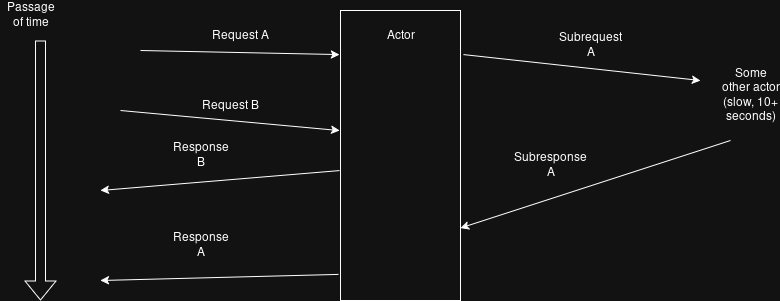
It seems the the actor concept as presented in that blog post doesn't fit at all. I need to be able to service other requests while the slow operation is in progress. What I would have done before would be to use pure message passing with sequence numbers in the messages, but is there a better option here? One that lets me make use of async in Rust to define my state machine rather than having to manually split it up into pieces with message handling? Because right now I don't see the utility of async for actors.
Keep in mind I do need &mut self and can't really hold mutexes over await points (and I don't want to pay the performance or complexity overhead of mutexes in the first place).
In order to avoid XY-problem: the slow operation is downloading debug info from a debuginfod server (or loading it from cache) and then parsing that debug info using a rayon thread pool. I also have operations where I may have many sub-requests for a given parent request. The inputs are from the debugger frontend and I don't want to block user interactions just because it might be doing a slow operation in the background. Many operations can proceed just fine in my debugger even though it is doing slow things in the background. (I'm making a tracing debugger that never pauses the debugee, to be able to debug programs with strict timing requirements, these tend to fail with gdb or lldb. This is possible thanks to the power of eBPF.)