A trivial thing, which must be implemented somewhere: truncate a str, yielding a slice, to N UTF-8 chars. There's floor_char_boundary coming someday, in nightly, but this is so basic it must exist already.
fn first_n_chars(s: &str, n: usize) -> Option<&str> {
let (x, _) = s.char_indices().nth(n)?;
Some(&s[..x])
}
The usual caveats about the usefulness of this operation apply (the set of Unicode strings with N codepoints is not really a natural category).
2 Likes
Another caveat worth mentioning is that this is O(n).
OK, so I had to write it. Amazing that this isn't generally available. I just need it to truncate debug logging.
It's not that amazing; chars don't correspond to any specific UTF8 length, human-perceived length, or even human-perceived characters (despite the name).
If you just need "eh, chop it off roughly here (even if in the middle of a grapheme)", that's probably going to be the round_char_boundary feature eventually.
6 Likes
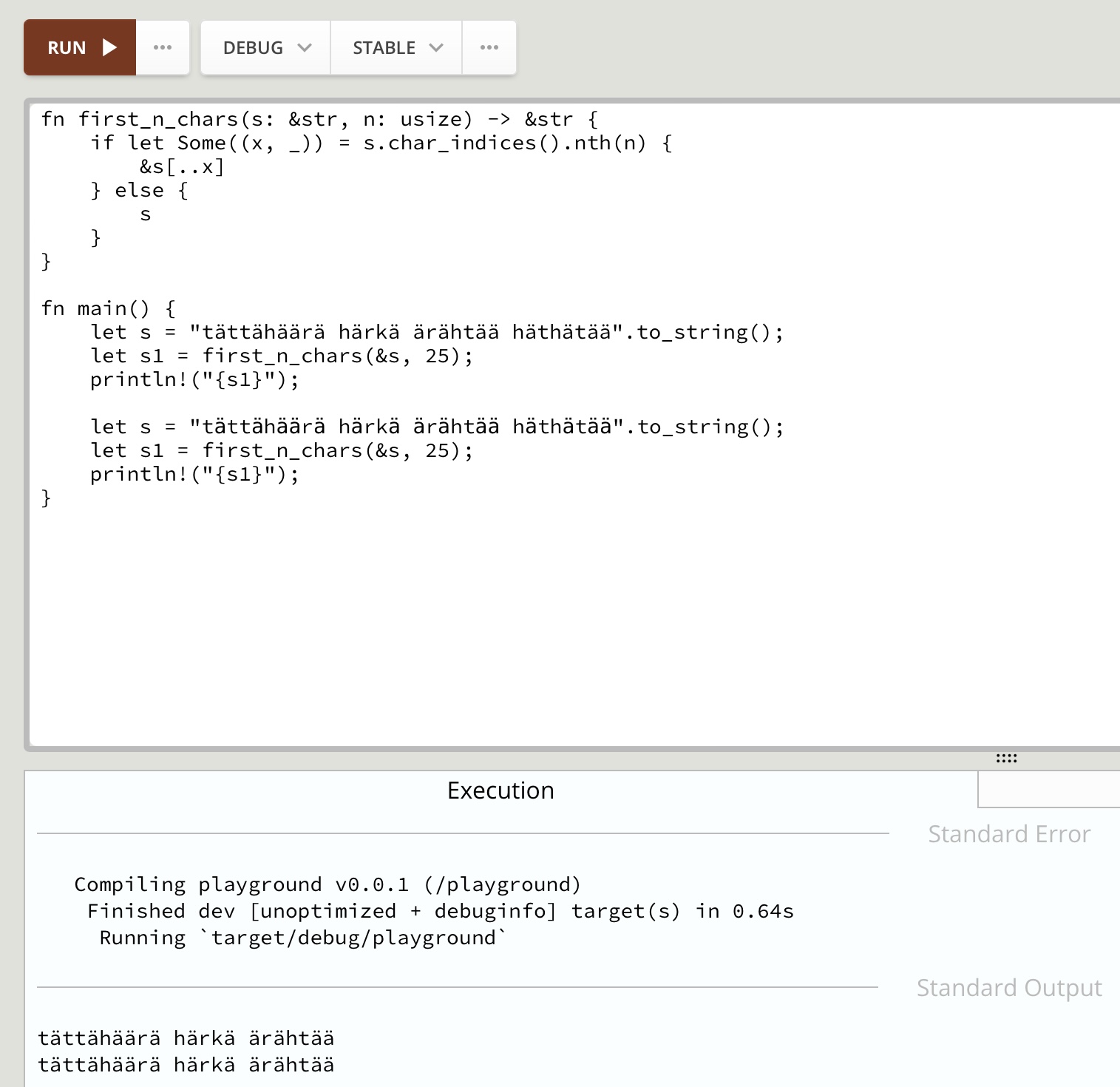
For example, guess what this code outputs? (playground)
The string is a valid Finnish sentence, albeit a slightly nonsensical one. The two versions are visually and semantically identical; they are merely encoded differently. For debugging purposes, either output is probably "good enough", even though the latter is clearly not what was intended. But for user-facing output, the latter would be just wrong!
let s = "tättähäärä härkä ärähtää häthätää".to_string();
let s1 = first_n_chars(&s, 25);
println!("{s1}");
let s = "tättähäärä härkä ärähtää häthätää".to_string();
let s1 = first_n_chars(&s, 25);
println!("{s1}");
2 Likes
When I run that in the playground, I can’t see a difference in the output:
Compiling playground v0.0.1 (/playground)
Finished dev [unoptimized + debuginfo] target(s) in 0.64s
Running `target/debug/playground`
Standard Output
tättähäärä härkä ärähtää
tättähäärä härkä ärähtää
If you copy-pasted, your system or browser or [...] may have normalized the text. (I see the different results on my system via either playground link or copy-paste.)
1 Like
I had the same experience running it in a mobile browser (Brave, iOS), but with desktop Firefox on Linux I get the intended effect. Maybe the two browser engines handle normalization differently?
1 Like
That’s the output from @jdahlstrom’s link, via iPad Safari. Interestingly, the font it uses renders the two versions of ä slightly differently (the second version is slightly taller), so I can see the difference in the source code editor. There must be some normalization going on in the build/run submission process.
Huh. Differs per browser or javascript engine or whatever I guess. I have had problems demonstrating the travails of unicode in the playground before. At least on my system, also, the editor and the output window have different levels of character-combining acumen (extended or legacy).
Great that we're back to "this website is bested viewed in my browser on my computer"...
6 Likes
The correct way to do this in text is to use crate unicode_segmentation. But being able to truncate UTF-8 str and still have valid UTF-8 is useful enough to have around as a standard function.
The official Unicode character set for Finnish is:
aA, bB, cC, dD, eE, fF, gG, hH, iI, jJ, kK, lL, mM, nN, oO, pP, qQ, rR, sS, s-caron, S-caron, tT, uU, vV, wW, xX, yY, zZ, z-caron, Z-caron, åÅ, äÄ, öÖ
but you can get the same visual effect using combining diacritical marks. You can also make messes by switching between left to right and right to left. This happens often in Hebrew, because modern Hebrew tends to have Arabic numbers left to right but text right to left. There's a Hebrew numbering system too, written right to left, but like Roman numerals, it's only used for dramatic effect today.
I had to write grapheme-aware word wrap once. It breaks on words if it can, graphemes if it must. That's close to the "right way" to do this. But what I'm doing this time is truncating long lines in debug log data from a 3D graphics program, for which linguistic accuracy is not a major concern.
4 Likes
More evidence that Unicode is very complicated.
Here is a constant time implementation that truncates to at most n bytes:
fn truncate(s: &str, n: usize) -> &str {
let n = s.len().min(n);
let m = (0..=n).rfind(|m| s.is_char_boundary(*m)).unwrap();
&s[..m]
}
4 Likes
Yes, but my point was that if such a function were in the std, it would likely be misused by many people who know enough not to naively truncate by byte but not enough to realize that chars != graphemes. In general Rust often takes the conservative stance when trying to protect users from shooting themselves in the foot.
2 Likes
Right, you can look for a UTF-8 boundary near the byte count you want.
Good point. The tables for identifying graphemes change over time, so those should not be in the low-level standard libraries. The official Unicode emoji modifier list is now on version 15.
It's probably best to keep that ever growing and writhing pile of worms of Unicode out of the standard library as much as possible.
Agreed. UTF-8 safe truncate, though, is a legit operation. It's well-defined, and since Rust str enforces UTF-8 validity, sometimes necessary. Unicode grapheme validity is a higher level issue.
This topic was automatically closed 90 days after the last reply. We invite you to open a new topic if you have further questions or comments.