ParseFloatError is public, but kind is private. Even FloatErrorKind is private.
Here are no way to get kind from error, not compare it with FloatErrorKind
Why is it so?
I think error kinds should be public, so user could check which error he got.
One of reasons to check would be error translation from English to other langues.
After reading riking message.
Thinking about errors.
Thinking about panic or result?
I come to conclusion.
result Err should come from function algorim themself. But problem coming from input should be validated before giving them to function.
This means, parse() should never return error Empty, because I should check if it is empty before trying to parse.
Validate before using, not after using.
This means f64.parse() don't need ErrorKind at all.
But what if you — or some other parse() user — doesn't check that and you end up trying to parse an empty string anyway? The type system in std currently doesn't have a way to enforce non-emptiness for a string, so any string that one calls parse() on could theoretically be empty, so the parse()/FromStr implementation needs to check for & handle that. Given that, you shouldn't need to or bother to validate the string before parsing it, because the parsing already does that for you.
I don't mean parse don't need to check if string is empty. I mean, error message don't need to say string was empty. It just needs to inform it failed to parse and nothing else. So, here is no need to make kind public.
And user should not check if parse failed because string was empty, he should check it before parsing if he want to check. Not after.
To check if parse failed because string was empty is same as...
It is like you go out from home to street and from passers-by reaction (laught and pointed fingers) check out if you are dressed or naked. And if you are naked you return home to dress up.
You should check this before going out, not after. So, here is no meaning to check reason of failure after trying to parse.
Write the code with the straight-line path assuming everything is going okay, and in the indented blocks describe how to handle it being incorrect, potentially invoking expensive diagnostic routines. This is how rustc is architected: diagnostics (errors and lints) often have several steps of preparation figuring out, in the analogy, which exact piece of clothing is missing and using that to choose which error message to present.
As I was thinking I had split errors into two types:
Input errors
Algorithm errors
Could not think of more types of errors.
Often on input errors code panics, and on algorithm errors return Result. But not always, like on parse will return Result.
But you as parse() user will know more about string you are giving, than parse algorithm. It can not only be empty. Here can be more diffirent problems.
In my country float numbers can be of two types:
1.0 - For use in English applications, because not all applications work with comma
1,0 - For local use, because in my country numbers are writen with comma.
Before using parse() on 1,0 I can check if number have comma and replace it with .
But algorithm can't do it. It only parses 1.0 types. Nor it can know if it should check or not.
And that if my number is like this: 1 000,01 or this 1.000.000,01
This is why it is best to validate input before using it and give parse() only valid number strings. And parse should not try to validate unknown things.
Because parse had two error kinds even if they are hiden I was thinking it is parse job to do all validations. But thinking more about possible strings of numbers, I come to conclusion it is not parse job to validate input, but my. So, just returnint error if it fail to convert is enough.
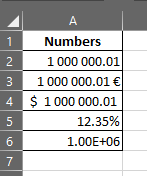
Here are far too many number formats, for parse() to convert to f64. And all of them are valid numbers in excel. This numbers only use . as decimal seperator, but it could also use , as decimal seperator.
This is why I say it is programers job to validate string and convert it to standart format, before giving it to parse().