That's why I brought up latency and pipelines. Even if most of the time is taken by fetching from the external API, you have two sources of latency to deal with:
- Latency from the API call.
- Latency from the DB insertions.
Without a "pipeline" (i.e., the naive approach), each task will first be blocked by the fetch and then also blocked by the DB insert. In other words, the operations are sequentially executed. You can't start the next API fetch until the current DB insert completes.

Even if you have N tasks, the total latency is still bounded by both calls. A "pipeline" splits up the API and DB operations so that they are logically independent of one another. In theory, this means that you can have a task that fetches the next batch from the API when it is ready, without waiting for any DB operations. The DB operations are inherently dependent upon results from the API.
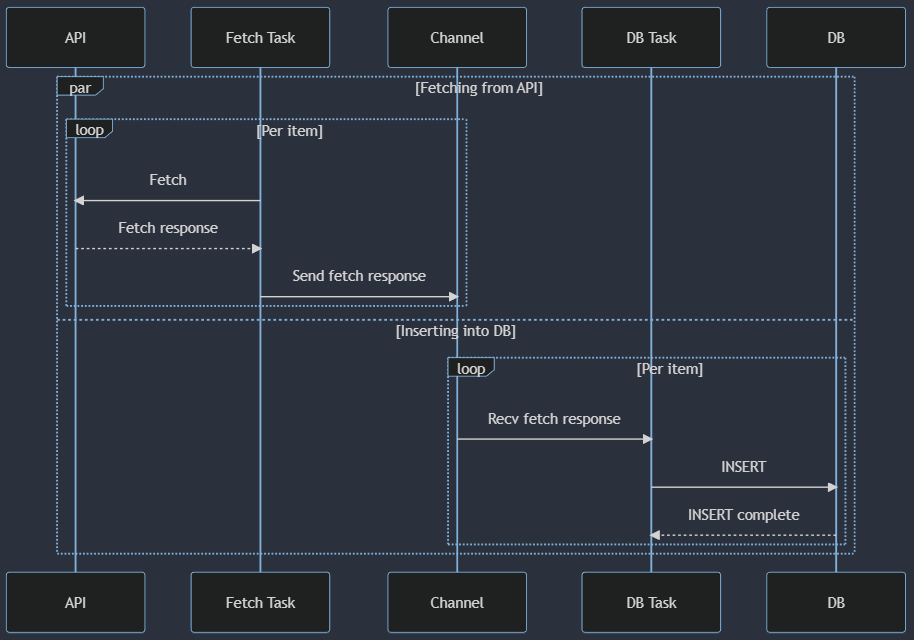
Here, we have two tasks with separate roles. They share data with a channel (mpmc) and operate independently. The fetch task grabs the next batch from the API as soon as it is able (after potentially blocking on the channel). The DB task inserts the next available batch (after potentially blocking on the channel).
Now you can have N fetch tasks and M DB tasks. Scale them independently, etc. This design has an issue that the channel may become a bottleneck from contention. Given that the tasks take multiple milliseconds and there are only 5 of them, you probably won't have any contention issues .
But this does have at least one advantage: a large N (number of fetch tasks) can parallelize many API calls to amortize the API latency without incurring any DB latency, assuming that either, 1. the DB inserts are orders of magnitude faster, or 2. your channel is unbounded or at least large enough to hold all of the batches. Keep in mind that a large channel is not bullet-proof! It basically destroys the advantages of back-pressure and can easily lead to lower resilience. It's an in-memory queue that goes away when the process dies.
Now is also a good time to bring up Amdahl's law. In simple terms, it just means that you can only make a system as fast as its slowest part. Throwing out a random number again, say that the API fetch takes 100 ms. Even with everything else fully parallelized, the fastest that the whole process could theoretically run is in 100 ms + 12 ms, because you cannot reduce the latency of that API fetch by "parallelizing it further" and the DB inserts depend on the API fetches. (And the sequence diagram is a visualization of this property.)
This is a theoretical minimum, of course. You are more likely to be bounded on the number of concurrent API requests and concurrent DB inserts than anything else. And it leads directly back to your observation that having a queue may not make much of a difference at all. You might be able to save a minute or two out of the 7 total. But it's mostly going to be bound on how long it takes to read everything from the API.