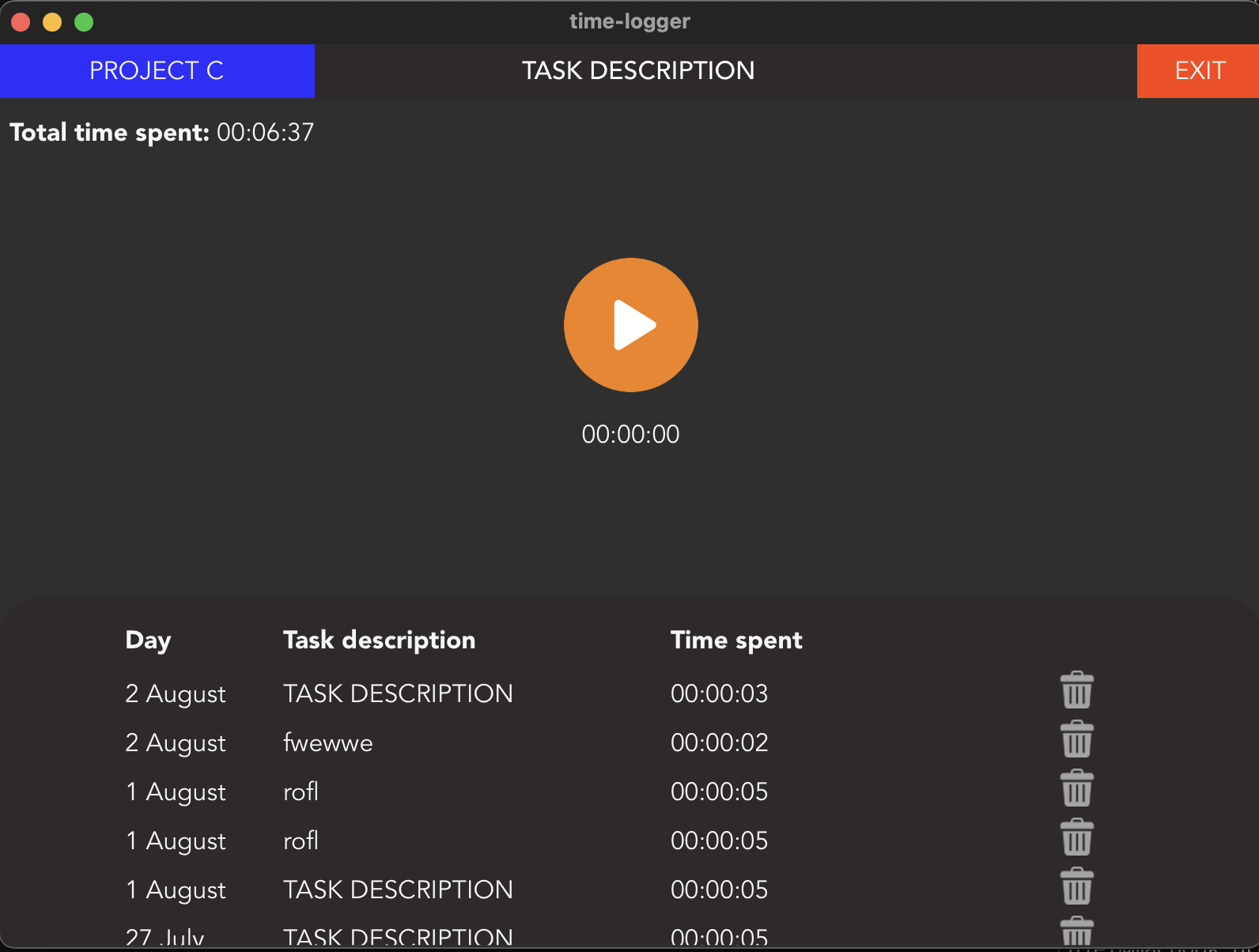
I changed some of the code and changed the structure. I am once again asking if I could PLEASE get a code review. I am self-teaching and am not using Rust in team-projects. So without someone being critically for my code I won't ever be able to improve myself in Rust.
I am not asking for a line-by-line detailed review, just some pointers regarding readability, error-handling, structure,...
I quickly skimmed through the code, so I can't say I found every problem I could, but here we go:
in main:
let is_playing = Arc::new((Mutex::new(false), Condvar::new()));
let first_click = Arc::new(Mutex::new(true));
let seconds = Arc::new(Mutex::new(0));
let reset = Arc::new(Mutex::new(false));
Putting a full Mutex around primitives is wasteful and non-idiomatic; use AtomicBool and AtomicU64 instead.
in tauri_commands: fn play() and fn save() have very long signatures. Pull the 4 and 5 arguments into respective structs. Or if you can't do that, at least use line breaks.
in config: what's the point of the Lazy? Why not simply:
Or if you are using Lazy, at least use the opportunities that it provides; e.g. instead of the relative path (which is very brittle), place the dotenv relative to $CARGO_MANIFEST_DIR.
Also, RUSTY_TIME_LOGGER_PATH itself should be a PathBuf, not a string.
At the same place (in the definition of SELECTED_PROJECT_PATH), and in many other places, e.g. utils/fn_utils, you should not be using string formatting to build paths. PathBuf::from(format!("parent/{child}")) should be parent.join(child). I mean this is just an abomination:
Three (!!!) different conversions just to join a path with a filename! That can't possibly be the right way.
The mods fn_utils and csv_utils have uselessly stuttering names. They are already in utils, aren't they. The CSV one should simply be called csv; the fn one is weird, fn is a non-descriptive name, you should rename it.
Anyway, in fn_utils, there are a bunch of problems with the code, too:
Do I understand it right that this piece of code:
match std::fs::read_dir(std::path::Path::new(format!("{}/timelogs", (*config::RUSTY_TIME_LOGGER_PATH)).as_str())) {
Ok(mut dir) => {
if dir.next().is_some() {
return Ok(());
}
},
Err(_) => {}
}
is simply a very roundabout way of writing Path::exists()?
If so, simply don't do it, if (not exists) { create() } is a common beginner mistake and leads to a TOCTOU race condition, as the aforementioned documentation itself clearly states too.
In fn counter(), you are cloning reset, but there's no reason for that. Omit reset_clone and just use the original reset.
This whole code block:
let mut reset_lock = reset_clone.lock().expect("Could not set lock on reset state");
if (*reset_lock) == true {
start_time = std::time::Instant::now();
total_pause_seconds = 0;
*reset_lock = false;
}
drop(reset_lock);
could be replaced by
if reset.compare_exchange(true, false, SeqCst, SeqCst).is_ok() {
total_pause_seconds = 0;
}
BTW, if (*reset_lock) == true is itself just an overly complicated way of writing if *reset_lock.
in fn get_selected_project(), you are discarding the whole potential I/O error and simply returning a non-informative String error. Furthermore, you are manually re-implementing Result::map_err(). Consider at least using anyhow and do:
fs::read_to_string(&the_path).context("Could not select project")
Your csv_utils is completely naïve and very inefficient:
CSV is not a simple format. The moment you start writing and parsing strings, you have to think about escaping (e.g. commas and newlines). If you want to read and write CSV correctly, use a dedicated crate.
But! You shouldn't be using CSV here at all! You are appending rows one-by-one, re-opening the file upon every single row. But what's even worse, you are reading and re-writing the entire file every time you want to delete a row! This results in quadratic runtime, and will grind your process to a halt once a couple thousands of rows have accumulated.
What you need here is a database; try SQLite.
In task_services:
let date_str = format!("{} {}", today.day(), today.format("%B").to_string());
The outer format!() is pointless, and so is the inner .to_string() – the whole point of DateTime::format() is that it returns a formattable type. This whole line should be replaced by
let date_str = today.format("%e %B").to_string();
In the same module, you are again throwing away useful semantic errors and making your errors stringly-typed, as mentioned before.
Task::new() should take an owned String; currently, it clones unconditionally, even though its usage in action_services() clearly makes that unnecessary.
project_service just has the aforementioned problems (TOCTOU, bad errors, stringly-typed paths)
Hi! Thanks a lot for your review! It helped a lot. I already implemented a few things and will continue with the rest.
match std::fs::read_dir(std::path::Path::new(format!("{}/timelogs", (*config::RUSTY_TIME_LOGGER_PATH)).as_str())) {
Ok(mut dir) => {
if dir.next().is_some() {
return Ok(());
}
},
Err(_) => {}
}
This however, is not to check if a path exists, but to check is a specific directory is empty.
The biggest change is the following: I initially did the time tracking in the back-end, I moved this to the front-end and when the save-button is clicked the amount of passed time is send to the back-end. This works a lot smoother.
Strong disagree on that one. Wasteful - it's a tiny global state, who cares. And a mutex often amounts to an extra word or two, that's a tiny price for the semantics it provides. Non-idiomatic - that's just false.
The last thing a novice needs is to bother with subtle implications of synchronization orderings. Unless one specifically writes a high-performance concurrent algorithm, the mental overhead and added possibility of subtle bugs with atomics is just not worth it. Use a Mutex or RwLock and spend your time on more important things.
And no, sprinkling SeqCst is not a substitute for properly thinking about synchronization, and doesn't magically solve the issues.
It's absolutely not false. You'll never see Mutex<bool> in real, high-quality code or as a recommendation.
And that's why they can just default to SeqCst.
If the mutexes are independent, then you can't get ordering guarantees across separate variables anyway. Mutexes are not magic — they are implemented in terms of atomics. (In fact, the whole acquire-release terminology of atomics comes from their first and primary use in locks.)
So no, OP wouldn't introduce "subtle bugs" by swapping the locks for atomics in the code above.
When two obviously very experienced people strongly disagree, they are probably both right, and in this case I really think it's true. Or anyway, I agreed with both of your arguments. ;-^
It really is rare to see Mutex<primitive> for something that can be a simple Atomic. And using Atomics, especially compare_and_exchange which is more than just a boolean flag or integer counter, isn't the best thing to try for someone new to Rust -- unless perhaps they are already familiar with atomics.
@ONiel, you should tell us what works for you. Do you have any previous experience with atomics? Any questions or confusion about compare_and_exchange or the use of SeqCst?
That's not bacause of bool. That's because you are unlikely to lock just a simple primitive. In production code that would be Mutex<State> or Mutex<Database>, where the inner types hold whatever state necessary. Which may very well be just a single bool or u64, but that's not relevant.
SeqCst is not a safe default in any way. x86 always ensures SeqCst for all memory operations. Did it eliminate concurrency bugs? No.
If you only care about updating a single integer atomically, you don't need SeqCst. A simple Relaxed ordering is enough. But that is very rarely what you need, you usually need some guarantees of ordering/atomicity with respect to other atomic and non-atomic operations. And SeqCst gives you none of that.
So just use a Mutex and be explicit about which operations happen atomically. Problem solved.
You lock the mutexes in sequence and trivially ensure the ordering, if it matters.
I have only ever used Mutex in combination with Arc. Arc to share the data across multiple threads and Mutex to have the locking-mechanism. Never used Atomic and never heard of SeqCst.
Thanks! I recommend sticking with Mutex for now and adding the use of atomics when you have some time to learn about them. One approach would be to try modifying this project to use atomics instead of Mutex<primitive> and do a little reading, then discuss it here in separate posts. The first couple chapters of Mara Bos' online book introduces them.
I still have some TODOs and the code is still not 100% optimal. But currently the application is usable for me and it does what I need it to do. I will improve it later.
x86 does not ensure SeqCst for all memory operations; it ensures Acquire for loads, and Release for stores, but not AcqRel or SeqCst unless you explicitly ask for non-default behaviour.
But a good default for atomics is to use Relaxed, not SeqCst, because SeqCst almost certainly implies more than you're thinking about while simultaneously not being as strong as you want, whereas Relaxed is likely to be either what you want (if only the value of the atomic itself matters), or sufficiently weak to show bugs (if you depend on an atomic access affecting the values you see in other variables).