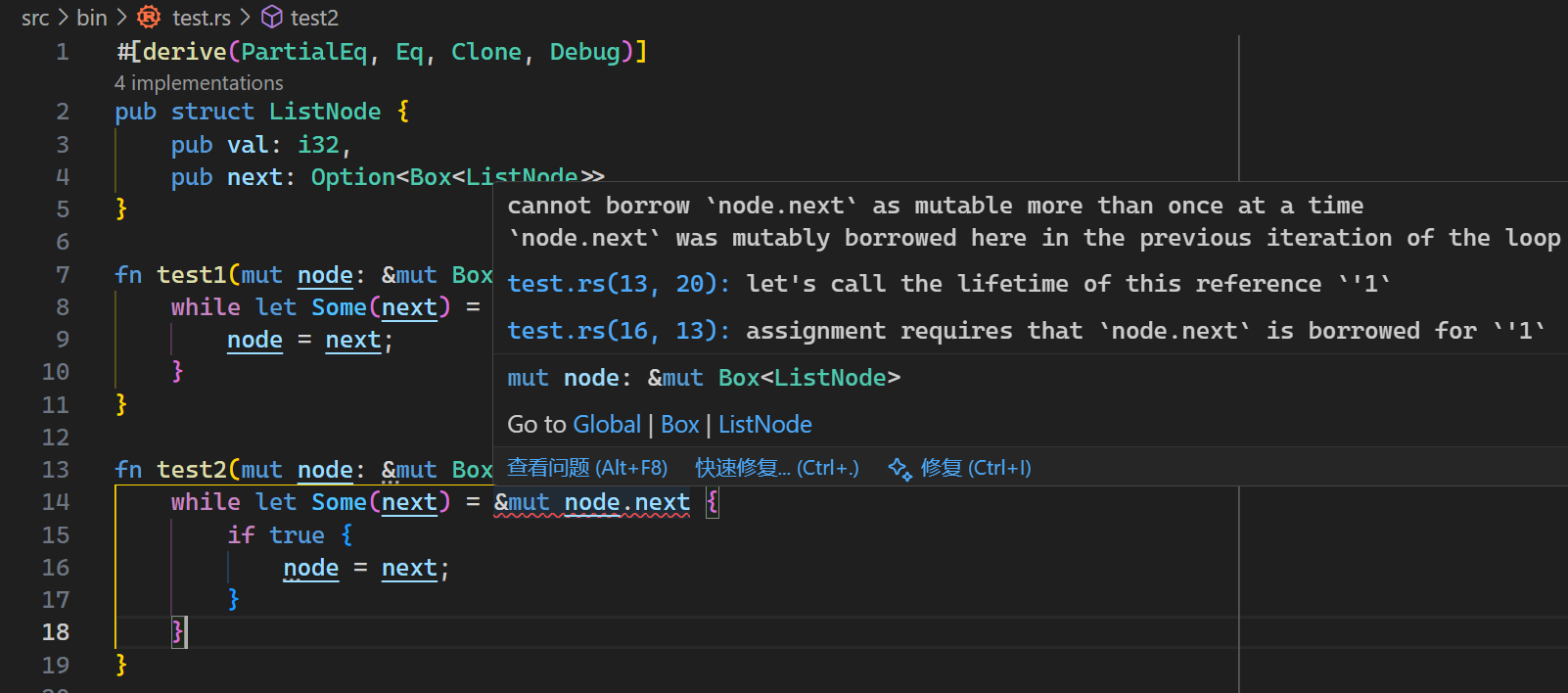
The compiler thinks test1 is fine but treats test2 as illegal because it "cannot borrow node.next as mutable more than once at a time". Why does adding an if statement cause such a drastic difference? Why isn’t the same error reason applied to test1? In my view, test1 is already illegal because next and node are both mutable reference to the same object.
you are Borrowing node.next mutably
then Moving the mutable reference (assigning node = next)
and Trying to borrow the same field again on the next loop condition.
so in the second loop you are taking another mutable reference of the node.next
I was reading an old edition of the Rust book and noticed that several examples meant to fail actually compiled. It turns out the borrow checker has evolved a lot, especially with non-lexical lifetimes (NLL). I watched a conference talk about it (didn’t understand all of it), but the gist is that Rust is now smarter and more forgiving about when borrows end, so many old “won’t compile” examples now work.
so i think this has something to do with this code, (i'm new to rust as well)
A workaround would be adding a diverging else-branch:
fn test2(mut node: &mut Box<ListNode>) {
while let Some(next) = &mut node.next {
if true {
node = next;
} else {
return;
}
}
}
This must be a (well-known) shortcoming of NLLs relating to conditional control flow, albeit I can't explain it. I'm sure someone that can will see this topic and give you a detailed answer though.
Also, mandatory link whenever someone posts a linked list implementation:
let node2 = &mut node1.next;
let node3 = &mut node2.next;
let node4 = &mut node3.next;
But in test2, the borrow checker doesn't understand the if-statement. The borrow checker works (currently) in this way, that the if maybe is true, or maybe not. So there are two possible outcomes.
First, assuming the if true is true:
let node2 = &mut node1.next;
let node3 = &mut node2.next;
But when the if true is assumed to be false, the borrows become:
let node2a = &mut node1.next;
let node2b = &mut node1.next;
So node2 gets borrowed exclusively twice, which is not allowed.
The key thing is, the (current) borrow-checker does not reason about program-flow (deep enough).
There's a useful more general lesson here: rust cares about types, not values.
When it sees if true it doesn't think "oh, that's always true", it thinks "oh, that's a boolean, so might happen or might not".
You as a human of course notice the value as well, but the compiler intentionally doesn't. (The compilation is more stable to you changing things that way.)
+-----+-----------------+ // `node` originally points here. Then you reborrow
| val | next: Some(ptr) | // `node.next` and if it is some...
+-----+-------------|---+
|
+-------------------+
|
V
+-----+-----------------+ // ...you overwrite node to point here, which is
| val | next: Some(ptr) | // somewhere else.
+-----+-------------|---+
|
:
The other key portion is that overwriting a reference "kills" the borrow it's associated with. Which is why this also works:
struct Example(u64, u64);
impl Example {
fn example(&mut self) {
let mut r = &mut self.0;
*r += 1;
r = &mut self.1; // <--
self.0 -= 1;
*r += 1;
}
}
Because the compiler recognizes that overwriting r "kills" the borrow of self.0, so the subtraction isn't an error.
When it's possible* to loop without overwriting node, that's when the borrow checker error comes up.
And what is considered possible* is what the last couple comments are discussing. It's intentional that values don't effect the control flow/unreachable code analysis. Adding the return branch means you either always overwrite node or do not loop; without the return, you may loop without overwriting node (as far as the compiler is concerned).
Thanks for your reply. I’m starting to get a sense of how the borrow checker views an “assignment” to a borrow and how it treats an if statement. But I still don’t understand why my code is invalid. I unrolled the loop, which should make things clearer:
fn test3(mut node: &mut Box<ListNode>) {
{
let next1 = node.next.as_mut().unwrap();
if true {
node = next1;
}
}
{
let next2 = node.next.as_mut().unwrap(); // error: cannot borrow `node.next` as mutable more than once
}
}
next1 borrows node.next, and then inside the if statement the borrow of node might get overwritten or might not. But either way, once we exit the first block, next1 is gone. At that point, in my view, nothing is still borrowing the previous node.next. So why does creating next2 still trigger an error, and why does it claim the first mutable borrow occurs at the line where next1 is created?
Your code is not invalid. Rather, the borrow checker is unable to prove to its satisfaction that your code is valid. That’s all. There is no deep reason why this code should be rejected; it just is, for now.
To expand on this: it is provably impossible to exactly reject invalid code with no false positives and no false negatives. This is a direct consequence of Rice's theorem - Wikipedia
In short, it can be shown that you can never get the answer exactly right for any semantic property[1] that doesn't hold for none or all possible programs. The best you can do is to classify into yes/no/don't know. Then, depending on if you prefer false positives or false negatives you group "don't know" into yes or no.
The borrow checker rejects code it can't prove is safe, while traditional linters instead accepts code they can't prove is bad.
As opposed to syntax properties like "does this source code contain any for loop". ↩︎
I do hope we do not bring out Rice's theorem when the failure case is quite simple though. While perfect borrow checking is impossible, current Rust is far from perfect. I think we can have huge improvements before Rice's theorem ever matters.
Sure, there are many ways to make it better. But in the limit, it can never be perfect.
And some analysis to bring it close to perfect will likely be so expensive that it isn't worth the compile time cost. (One trick to mitigate this is to use a simple model, and only if it fails fall back to a slower and more accurate model, I believe this is how Polonius works.) One thing that will likely never happen for instance is interprocedural analysis, as that would be very expensive, and also hard for humans to follow. Having the borrow checker be per-function is a limiting factor in accepting valid programs though.
The reason (in the current borrow checker) is similar to the explanation of Problem Case #3here. Variables don't change their type, and the type includes the lifetime, and (in the current borrow checker) that means that here:
let next1 = node.next.as_mut().unwrap();
if true {
node = next1;
}
next1 must reborrow node.next for the lifetime that comes from outside the function, which is longer than the entire function, so that it can be assigned to node. In order for it to compile, you need a more refined notion of lifetimes, something that is more location and flow sensitive.
(At least, that's my interpretation. The issue linked below may have more technical details.)
polonius=next can handle this unrolled version, but not your loop version. The loop version is an instance of issue 47680 I believe (also talked about in the blog post). The version of Polonius (~"next") likely to stabilize isn't expected to entirely solve 47680, but the hope is still to be able to do so in the future. There's a summary here (not that the full implications are obvious to a casual reader).
AFAIK the issue here is that node needs to be reborrowed for different lifetimes depending on the if condition (which the compiler doesn't care it's always true). If the branch is picked it needs to be borrowed for its entire lifetime, otherwise it needs to be reborrowed until the end of the current iteration. The current borrow checker can't reason about this control flow dependent borrowing, so you get an error.
That's just not true in general. It depends on how you define "invalid code". For instance, in many languages type checking works perfectly in every case: it accepts every valid program, according to the type rules of the language, and rejects every invalid program.
The example here is simply that the lifetime rules are stricter than they need to be. It has nothing to do with Rice's theorem because we are talking about static rules, not about analyzing runtime behavior.
To illustrate the difference, this is invalid code even though it never does anything wrong at runtime:
let mut x = 7;
if false {
x = "abc";
}
If we wanted to allow stuff like that, we'd run into Rice's theorem, but this is not necessary or useful.
I would argue that the lifetime rules are a static approximation of the real runtime rules of "contains no memory or thread safety issues"[1]. As such Rice's theorem very much applies.
That is an example of a syntactic property (in the type system), not a semantic property though, as I clarified in my next paragraph in the post you quoted. Yes the wording in the first paragraph was a bit loose.
Which is vague, you would need to define exactly what qualifies as a memory or thread safety issue to make this rigorous. ↩︎