Thank you so much for the detailed response. It was quite illuminating. The only thing I am confused about in your response is the semantics of referencing a dereference. For example, the following code (based on your example would compile):
let mut owned = String::new();
let a = &mut owned;
let b = &mut *a;
println!("{a}");
However, the following code would not:
let mut owned = String::new();
let a = &mut owned;
let b = &mut owned;
println!("{a}");
Why is there a difference? In both examples, isn't b technically mutably borrowing from owner (albeit in the first example, it's through the dereference)? I am a bit confused about the semantics of referencing a dereference here. I also am not familiar with this "chain of exclusive access" concept.
Yeah, that makes sense. I was just trying to get a reference to the value inside an Rc, so I was wondering if I could exploit deref in some way to do that.
The rule when stated briefly is "memory reachable through a &mut cannot be aliased", or un-jargoned, "&mut implies unique access". That's just a core part of the language, upon which the memory safety guarantees rely. Thus violating the rule is instant undefined behavior, and since Rust doesn't have UB in safe code, if the compiler can't prove to itself your code obeys the rules, it throws an error.
The rule is sometimes phrased as "you can't have two &mut at the same time", or "you can't have a &mut and a & at the same time", but as the working examples illustrate, that phrasing is a bit too simplistic. It's really more like, "you can't have two active at the same time." This is what allows reborrowing, which is sort of like a sub-borrow:
let a = &mut owned;
let b = &mut *a;
// We're both `&mut String` but `b`'s borrow depends on `a`'s borrow.
// We didn't move `a` to get the reborrow,
// And the lifetime for `b` might be shorter than that of `a`
//
// `a` is unusable (inactive) while `b` is active, but not dead yet.
// Or alternatively put, using `a` again "kills" `b`'s [sub-]borrow
// (and any use of `b` thereafter emits a compiler error)
// ((And both are borrows of `owned`, so using that kills both))
These reborrows are actually all over the place: when you call a method that takes &mut, a reborrow is performed, otherwise you couldn't do something like
Because &mut can only be moved, not copied. So you get a reborrow here whose lifetime is only as long as the call to push, and can use v again afterwards. The reborrow here is implicit; &mut *a is just the explicit way to write it. You can also reborrow only parts of the original borrow.
let v2 = &mut v[0..5]; // [] acts like a * dereference
let field = &mut object.f; // So does field access
Fine then, what exactly determines this "active or not" quality? Unfortunately, there is no formal specification. The closest thing that's been proposed so far is stacked borrows. However, stacked borrows doesn't quite cover everything Rust allows today, and will probably be expanded at some point. [1] (If you run Miri,[2] it uses a version of stacked borrows which has already evolved a bit from the paper.)
In terms of what we have discussed here,
let mut owned = String::new();
let a = &mut owned;
let b = &mut *a;
println!("{a}");
owned has a conceptual stack, creating a pushes an exclusive access based on owned, creating b pushes an exclusive access based on a, and then using a pops b (killing its borrow) so that a can be on the top of the stack again and get used. Because it got popped, b can no longer be used. Using owned would have popped everything.
Where as here
let mut owned = String::new();
let a = &mut owned;
let b = &mut owned;
println!("{a}");
In order to create b, owned must be at the top of the stack, so a gets popped and it's an error to use it afterwards. [3]
This "I'm still on the stack" property is the same thing I was trying to convey with the "I have a chain of exclusivity back to the owner" discussion. Both are mental models to reason about why you get the errors you do, by approximating the analysis the compiler actually does.
For much more technical discussion, but also in my opinion much harder to reason about one, you can read the NLL RFC. We have most of NLL today. [4] The borrow errors you get today are actually from the NLL implementation.
Or for a different approach with the same goal, you can read the Polonius [5] blog posts
Now, one could imagine this particular case being accepted -- if b is never used, or maybe b could be allowed to activate after a, etc. I.e. this is another case where Rust could evolve and break these mental models. The trick will be both getting it right (not creating soundness bugs) and not making it something too complicated for humans to reason about. ↩︎
We don't have the piece that solves problem case #3 yet. ↩︎
That makes sense. Thank you so much for the detailed response. The concept of stacked borrows resonates well in my mind (as you can probably tell by my profile picture ).
Actually, now I that I think about it more, the borrowing examples you mentioned makes sense in terms of using a stack as a mental model, but I still don't understand how the compiler analyzes lifetimes. I know that it is based on usage of the reference, but that's as far as how my understanding goes.
For example, in the example below, the lifetime of a is extends from lines 3 - 4, and the lifetime of b is limited to line 5. Since these lifetimes are non-intersecting, this code compiles cleanly with no errors.
But, in the code snippet below, the lifetime of a extends from lines 3 - 5, and the lifetime of b is limited to line 4. Since these lifetimes are intersecting, the code does not compile.
However, in the code snippet below, the lifetime of a extends from liens 3 - 5, and the lifetime of b is limited to line 4. These lifetimes are intersecting, but why code does compile? Is it because the compiler treats *a and owned as different entities?
The compiler knows that b is a reborrow of a's borrow, yeah. The compiler doesn't used stacked borrows, but let's look at it through that lens, as it's easier to understand.
You seem to be thinking of the first two examples as (contiguous?) regions that do or don't overlap, and that model works for explaining why they compile or don't. But it's not taking into account the "stacking" nature of reborrows, which is what let's example 3 compile.
In example 3, 'b is a reborrow of 'a -- it's stacked above'a. So it's still okay to use 'a -- although you'll have to pop 'b to do so.
Therefore, the stacking model allows for more uses than the "any intersection is bad" version.
In example 4, stacked borrows keeps tracks of all of these reborrows. Once you use a, the stack gets popped a bunch, killing 'b, 'c, and 'd. Then it's an error when you try to use d again.
Another formulation of how a stack works is to consider things to be well-nested. This is pretty simple at the single-borrow level: I create a borrow of owned, and all uses of that borrow have to be before the next use of owned [and the drop of owned or end of its lifetime is a "use"]. A valid borrow must be nested within the uses of what is borrowed.
It's a little more complicated with deeper layers: Every use of a reborrow has to be before the next use of whatever we reborrowed from, and transtively anything they borrowed or reborrowed from.
The pattern to avoid is a break in the nesting: AXBX where X borrows or reborrows from A, and B is A or something A transitively is a borrow or reborrow of.
In nesting terms,
Example 1
a is used on lines [3..=4], nested between uses of owned on [3..=5]
b is used on line 5, nested between uses of owned on [5..=6]
Example 2
a is used on lines 3 and 5 and that is not nested between uses of owned on [3..=4]
b is nested on line 4 (in [4..=6]) but that doesn't matter due to the above
Example 3
a is used on lines [3..=5], nested between uses of owned on [3..=6]
b is used line 4, nested between uses of ownedora on [4..=5]
This is a transitive case but we didn't need the transitivity, just the relation to a
Example 4
a is on lines [3..=4] and 7, nested in [3..=9] (owned)
b is on lines [4..=5], nested in [4..=7] (owned, a)
c is on lines [5..=6], nested in [5..=7] (owned, a, b)
d is on lines 6 and 8, not nested in [6..=7] (owned, a, b, c)
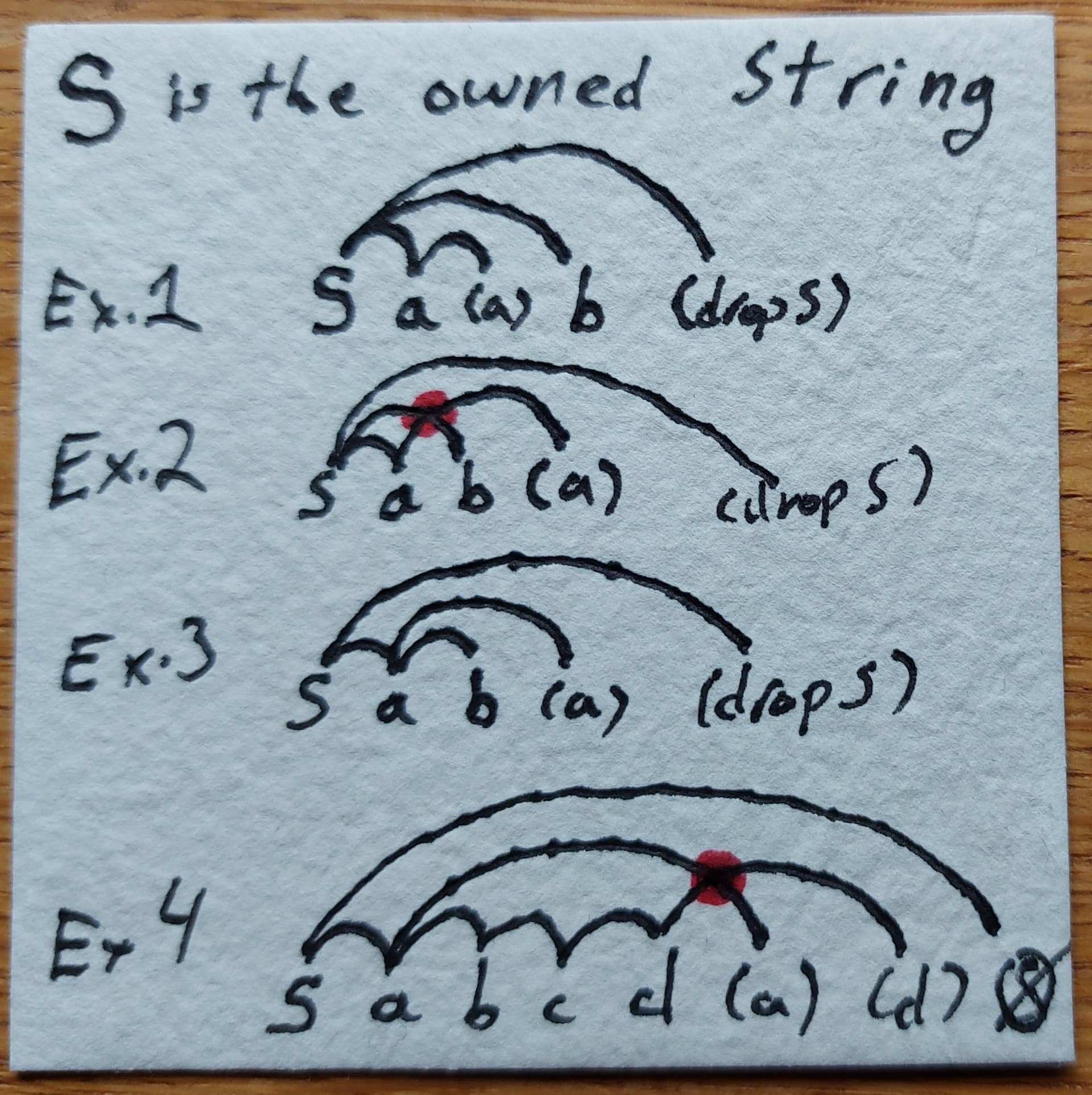
Graphically on a timeline, you can draw arcs between
Borrows or reborrows and what is being borrowed or reborrowed from
Subsequent uses of the borrow
And if all the arcs are nested, you're fine; if there is an intersection, that's an error.
It's a pain to do with code comments (especially once you get into loops), so here's a drawn version.
In terms of "chains of exclusivity", valid uses of borrows have a non-intersection path back to the owned data [2], and the use of something like (a) or (drop S) kills all chains under the arc that lead back to the left endpoint (so in example 4, (a) killed bc and d).
I'm ignoring shared borrows and everything except exclusive borrows in this whole post. ↩︎
Thank you so much for the detailed response. I think this line is key. The concept of stacked borrows makes more sense now. I think I fell into the trap of clinging too hard to the "any intersection is bad" version because of what I learned in the book (no complex examples of reborrowing were given in the book). If I have it right, any use of a borrow should be used before another use of what that borrow is borrowing OR if what that borrow is borrowing is borrowing something else, it also should also be used before another use of that (transitive nesting). Otherwise, the borrow becomes invalid. I have one final question (I promise ): are there any obscure examples where this mental model fails to explain why certain code compiles/does not compile?
I don't think that "any intersection (mutable aliasing) is disallowed" is a bad mental model, you just have to extend it a little bit in the context of reborrowing. When you have a mutable reference a and you reborrow it creating mutable reference b, then as long as b is in use, the original a is "frozen", ie. you are temporarily banned from accessing it. In this manner, there will be no real (usable/exploitable) mutable aliasing.
Stacked borrows is a bit more complicated than has been summarized here due to shared borrows and interior mutability, so you would have to work that in to your model
It also gets messy when you start mixing diferrent data types together, in terms of diagramming things out anyway
And even then the idea of stacked borrows is to be a runtime analysis which is sort of an "upper bound" on Rust's (not formally defined) aliasing model, regardless of the current implementation
And thus can only ever be an approximation of the compiler's static analysis
E.g. NLL Problem Case #3 will give you an error today, but is actually sound and accepted by Polonius, and if you forced it with unsafe I believe Miri would be fine with it
More generally, a main idea of unsafe is that sometimes the compiler cannot prove some safe code is sound (e.g. obeys the aliasing model) when it is
So ultimately it's just a tool, but I've found it to be a pretty good one. The only way to fully know why certain code compiles or doesn't compile is to fully understand the compiler. So understanding the NLL RFC or perhaps the Polonius approach will arguably get you closer to the technical reason why (as those are the static analysis that the compiler performs), but if I can see an error and trace it to a nesting violation or whatever, it's almost certainly unsound and I can just go "ah yeah fine, here's at least part of the probelm" and get to work trying to find a solution. At least personally, I find that easier than trying to reason about a shifting set of loans and regions in a flow graph.
It would be neat if there was something that could output an annotated version of your code with the compiler's lifetime / borrow analysis though. If it exists already and I'm just unaware, I'd love to hear about it.
Thanks for the detailed response. It's been a little bit frustrating with the compiler when you think that some code should or should not compile (esp. as a beginner), but I guess more experience and a rigorous understanding of Rust internals will help a lot.